ClickHouse® for Time Series Scalability Benchmarks
Our previous take on time series benchmarks (see https://www.altinity.com/blog/clickhouse-for-time-series) attracted a lot of interest so we decided to dig into more details. We conducted 3 different ClickHouse scalability tests using the same TSBS dataset and benchmarking infrastructure. In this article, we present results that happen to be quite interesting.
Introduction and test setup
For time series benchmarks we added ClickHouse to TSBS — a collection of tools and programs that are used to generate data and run write and read performance tests on different databases. The particular test we were using generates test data for CPU usage, 10 metrics per time point. In total, it generates 100M rows from 4000 devices (hosts). Then we repeatedly run 15 sample queries in several parallel workers and measure average query time. See more details in our previous article on this topic, where we tested ClickHouse against TimescaleDB and InfluxDB.
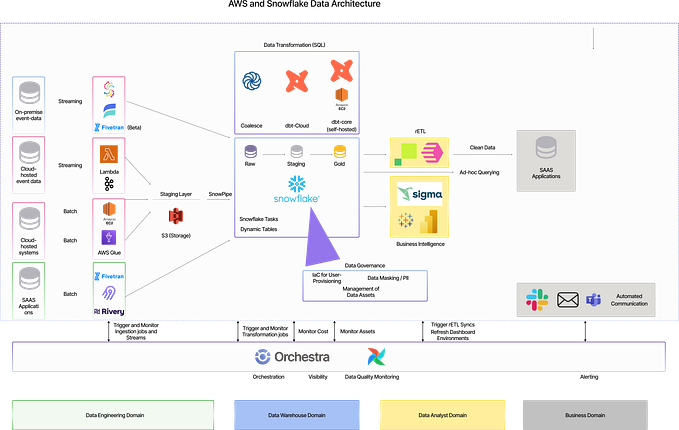
ClickHouse scales easily. It can be scaled not just by adding extra replicas — but also by adding extra shards in order to process queries in a distributed way. That makes it usable for very heavy workloads. For the scalability experiment, we set up a simple 3-nodes cluster at Amazon r5.2xlarge instances. Next, we distributed ‘cpu’ table containing metrics using a hash function of primary key columns tags_id and created_at. This gives even distribution and allows us to benefit from join locality at ‘lastpoint’ query. We have not tested ingest performance on the cluster. For ClickHouse, it is linear to a number of nodes if proper ingestion setup is used. Instead, we have just re-distributed data loaded during previous single node benchmark. The redistribution took about a minute, and at the end, every node stored ⅓ of original data, approximately 34 million rows per node.
Test queries and test methodology is the same: 1000 query executions of every query type run in parallel in several threads. We tested three different setups.
- For the first one all queries were run at single ClickHouse server by 8 workers as in original TSBS benchmark, and that was ClickHouse job to distribute query workload to other cluster nodes.
- For the second one, we split the same workload to 3 ClickHouse servers externally, running 3 query workers against every ClickHouse node. Since 8 can not be easily divided to 3, we had to add a 9th worker to make an even distribution on every node. That makes the slightly higher load on the system overall.
- And last but not least we tested how our 3-node cluster sustains x3 load: 8 workers per server.
As a reference point, we used results from the previous single-node benchmark.
Charts below show average execution time per query type. Results are split into two categories, as before: ‘light’ queries with millisecond response time, and ‘heavy’ queries that take few seconds to complete. Tests #1 and #2 are grouped together, while x3 load test is discussed separately.
Scalability test


Results are quite interesting. First of all, ClickHouse demonstrated that it scales for time series, and query time can be improved in most cases by adding extra nodes. The actual improvement is different between ‘light’ and ‘heavy’ query groups, and it holds pretty much the same inside the group.
For the ‘light’ queries there is a substantial difference if queries are executed against a single server or multiple servers. Fastest queries do not benefit from the cluster at all, until queries are distributed. It perfectly makes sense: such queries mostly rely on in-memory structures and CPU, thus reducing the load to the server makes the difference.
Contrary, ‘heavy’ queries benefit from the cluster, regardless of the entry point, with an exception of CPU intensive ‘high-cpu-all’ query. The most of the job is performed in a distributed part of the query, there are I/O intensive data scans, and reduced data size per server helps a lot.
Slight degradation of multi-entry vs. single-entry is explained by adding 9th worker: the load is 12.5% higher, and it is perfectly reflected in results.
Tripled load test


This is even more interesting! We increased the load and hardware three times, and we’ve got significant improvement on some queries, while others are pretty much the same. The increase comes from the fact that every server stores only ⅓ of the data, and even at triple load it pays off significantly. Note, that though we run 8 workers per node, as in single node scenario, the load to every node in the cluster has increased by x3, because every query from total 24 workers is distributed to all nodes. This is why performance is slightly worse on heavy queries, that are executed in a distributed way.
Conclusion
ClickHouse is not only fast for typical time series workload, standing very well against popular TimescaleDB and InfluxDB, and significantly outperforming them on computationally or I/O intensive queries. It also scales easily if system performance is not sufficient or data size does not fit a single server. It also scales very well when query workload is increased. That makes it a preferable solution for the time series systems with huge amounts of data or strong scalability requirements.
In the next article on this topic, we are going to benchmark and discuss different schema types that can be used in ClickHouse in order to store time series data. Stay tuned.
Find more ClickHouse updates in Altinity Blog.
Need help with ClickHouse? Get a FREE consultation with an expert!